| |
Bases de probabilité,
|
Les probabilités sont la base des statistiques. Les définitions des évènements possibles et le calcul des probabilités de voir un évènement se produire introduisent les lois de distribution et donc la loi normale, bases des statistiques.
Un exemple d'évènement en probabilité est : le nombre affiché sur le dé est pair.
Les fonctions et et ou sont utilisées : et veut dire que les deux conditions doivent être vraies, ou veut dire qu'au moins une des deux conditions doivent être vraies.
&= inter
Evénement contraire : A barre (A_)
A_ _ = A
( A ou B)_ = A_ et B_
( A et B)_ = A_ ou B_
Evénement incompatible
A et B sont incompatibles lorsqu’ils ne peuvent pas se réaliser en même temps (simultanément)
Probabilités
Oméga = ensemble fondamental (O)
A = la famille d’événements
(O, A) = espace probabiliste
p : Aà R application de A en R
Définition
on dit que p est une probabilité si les axiomes suivant sont vérifiés
quelque soit a de A : p(a) est dans [0 1]
p(O)=1
si a U b = 0 p(a union b)= p(a) + p(b)
si a1, a2,… est une suite d’événements qui s’excluent mutuellement alors p(a1Ua2U…)=p(a1)+p(a2)+…
Propriétés
0 événement impossible p(0)=0
a_ contraire de a p(a_)=1-p(a)
si b inclus dans a p(b)<p(a)
a et b quelconques p(aUb)=p(a)+p(b)-p(a & b)
a,b,c quelconques p(aUbUc)=p(a)+p(b)+p(c)-p(a&b)-p(a&c)-p(b&c)+p(a&b&c)
Ensemble probabilisé fini
O fini = {w1,…,wn}
A=P(O) ensemble d’événements
P : O à R
Wi à pi = p(wi)
O est un ensemble probabilisé fini :
pi > 0 pour tout i
p1+p2+…+pn=1
Probabilité de a
a inclus dans O, a=Uwi / wi appartient à a
p(a)=somme pi des wi appartenant à a
un ensemble probabilisé fini est dit équiprobable ou uniforme si p(wi) = 1/n
dans ce cas p(a)= nbr de cas favorables à la réalisation de a / nbr de cas possibles de O
1 dé : chaque face a une probabilité de sortie de 1/6
p(sortir un nombre impair)={1, 2, 3}/{1, 2, 3, 4, 5, 6}=3/6=0.5
a et b deux événements p(b) > 0
a & b est noté a.b
p(a/b)=p(a&b)/p(b)
p(a_/b)=1-p(a/b)
un dé probabilité de sortir un 5 ou un 6 = 2/6
probabilité de sortir un nombre impair 0.5 (vu ci-dessus)
p(5 ; 6/impair)=p(5 ;6 & impair)/p(impair)=p(5)/p(impair)=(1/6)/(1/2)=1/3
on déduit de la dernière formule les suivantes
p(a & b) = p(a)*p(b/a)=p(b)*p(a/b)
corrolaire p(a.b….z)=p(a)*p(a/b)*…*p(z/a.b….y)
Exemple
un lot contient 12 articles dont 4 sont défectueux. On tire au hasard trois articles du lot, l’un après l’autre. Calculer la probabilité p pour que les trois articles ne soient pas défectueux
a={les trois articles ne soient pas défectueux}
ai={le i-ème article tiré ne soit pas défectueux}
a=a1.a2.a3
p(a)=p(a1.a2.a3)=p(a1).p(a2/a1).p(a3/a1.a2)=8/12*7/11*6/10
cette fonction est la loi hypergéométrique
D=4, N=12, n=3 ici d=0
p(d)=C(d, D)*C(n-d, N-D)/C(n, N)
H1, H2,…Hn une partition de O
U Hi=O
Hi & Hj={0} si i#j
A un événement
A = O & A = U (Hi & A)
Formule des probabilités totales
P(A)=p(U (Hi & A))
=p(H1 & A)+…+p(Hn & A)
=p(H1)*p(A/H1)+…+p(Hn)*p(A/Hn)
p(A)=somme p(Hi)*p(A/Hi)

Théorème de Bayes
H1, H2,…Hn une partition de O
A un événement
Supposons que A est réalisé pour tout i on a alors :
P(Hi/A)=p(Hi&A)/p(A)
D’après le théorème de la multiplication on a :
P(Hi&A)=p(Hi)*p(A/Hi)
D’après la formule des probabilités totales on a
p(A)=somme p(Hi)*p(A/Hi)
Donc
P(Hi/A)={p(Hi)*p(A/Hi)}/ {somme p(Hi)*p(A/Hi)}
Exemple : trois machines A, B, C fabriquant respectivement 50%, 30%, 20% du nombre total de pièces. Le pourcentage de pièces défectueuses de chaque machine est de 3%, 4%, 5% pour A, B et C.
Si on prend une pièce au hasard quelle est la probabilité que ce soit une pièce défectueuse :
Probabilités totale = p(A)=somme p(Hi)*p(A/Hi)
P(A)=50%*3%+30%*4%+20%*5%=1,5%+1,2%+1%=3,7%
Supposons que l’on tire une pièce au hasard et qu’elle soit défectueuse. Quelle est la probabilité que cette pièce ait été produite par la machine A
Théorème de Bayes :
P(machine A / mauvaise)=p(machine A & mauvaise)/p(mauvaise)
=p(machine A)*p(mauvaise / machine A)/p(mauvaise)
=50%*3%/3,7%=40,54%
indépendance
on dit qu’un événement B est indépendant d’un événement A, si la probabilité pour que B se réalise n’est pas influencée par le fait que A soit ou ne soit pas réalisé
p(B)=p(B/A)
si A est indépendant de B alors
p(A & B) = p(A)*p(B)
exemple on jette une pièce de monnaie trois fois
O={FFF ; FFP ; FPF ; FPP ; PPP ; PPF ; PFP ; PFF}
A= le premier jet donne face,
B= le second jet donne face
A indépendant de B
P(B)=4/8=1/2
P(B/A)=2/4=1/2
P(A&B)=2/8=1/4=1/2*1/2
Certaines questions des sondages d’opinion sont si indiscrètes que les réponses risquent d’être mensongères. Un sondeur veut tourner cette difficulté par le procédé suivant.
L’enquêteur présente à la personne interrogée un disque de loterie bicolore : un petit secteur (bleu par exemple) mentionnant « faites une réponse mensongère » et un secteur complémentaire (blanc par exemple) mentionnant « faites une réponse véridique ». L’enquêté reçoit l’instruction de faire tourner le disque de la loterie à l’abri des regards et, selon que l’index de la loterie sera dans le secteur blanc ou le secteur bleu, de faire une réponse véridique ou mensongère à la question qui va lui être posée (avec réponse par oui ou par non). Cette réponse sera enregistrée par l’enquêteur sans qu’il sache ce qu’aurait été la réponse sincère.
a) Un échantillon de n personnes interrogées ainsi a fourni k réponses oui à une certaine question. Sachant que le secteur bleu est une fraction théta (noté t) du disque, estimez la proportion p, dans la population, des personnes dont la réponse sincère à cette question serait oui.
b) Quelle est la précision de cette estimation, mesurée par son écart type ?
c) La même précision pourrait être obtenue avec un échantillon de n0 personnes, si l’on pouvait en obtenir des réponses sincères. Evaluez le rapport n/n0 qui est une mesure du coût de ce procédé.
a) La probabilité d’obtenir une réponse oui est q=(1-t)p+t(1-p), donc p=(q-t)/(1-2t). k/n=q* est un estimateur sans biais de q, qui fournit un estimateur sans biais de p : p*=(k/n-t)/(1-2t).
b) k est une variable aléatoire suivant la loi binômiale (n,q) et a donc pour écart type racine(nq*(n-q)). C’est aussi l’écart type de k-nt=np*(1-2t), d’où l’on tire l’écart type de p*
s=racine(p*(1-p)/n+t*(1-t)/(n*(1-2t)^2))
La précision est meilleure si t est petit, mais t ne doit pas être trop petit pour rester crédible vis-à-vis des sondés.
c) Egalant cette dernière expression à la même expression où on a remplacé n par n0 et t par 0 (réponses sincères), on obtient :
N/n0=1+t(1-t)/(p(1-p)(1-2t)^2)
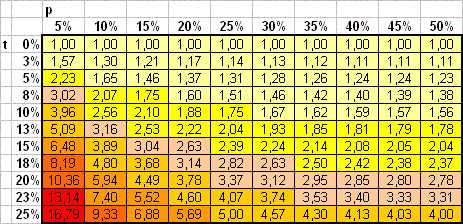
La coloration du tableau est obtenue avec le classeur téléchargable présenté sur la page segmentation.
![]()
![]()